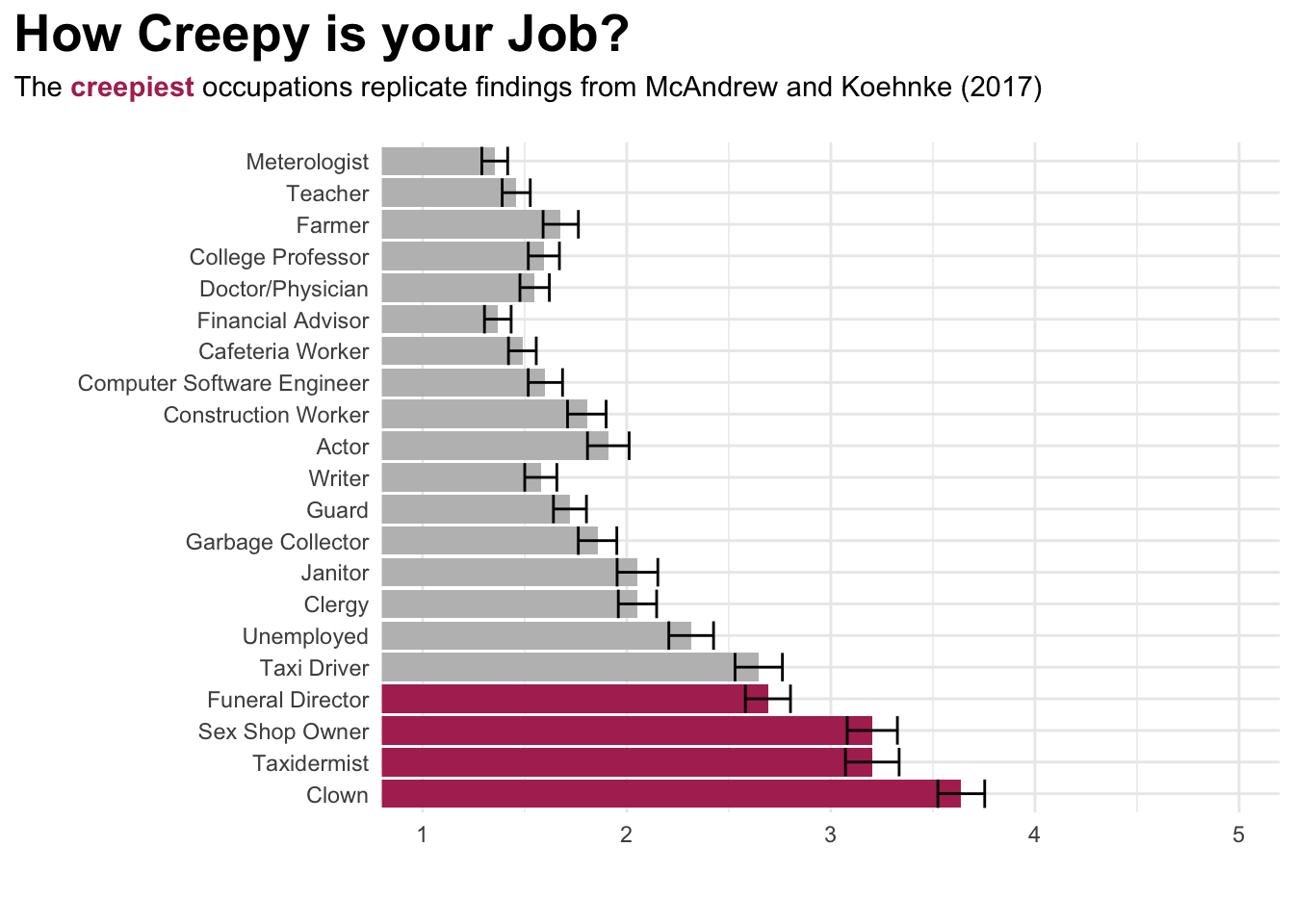
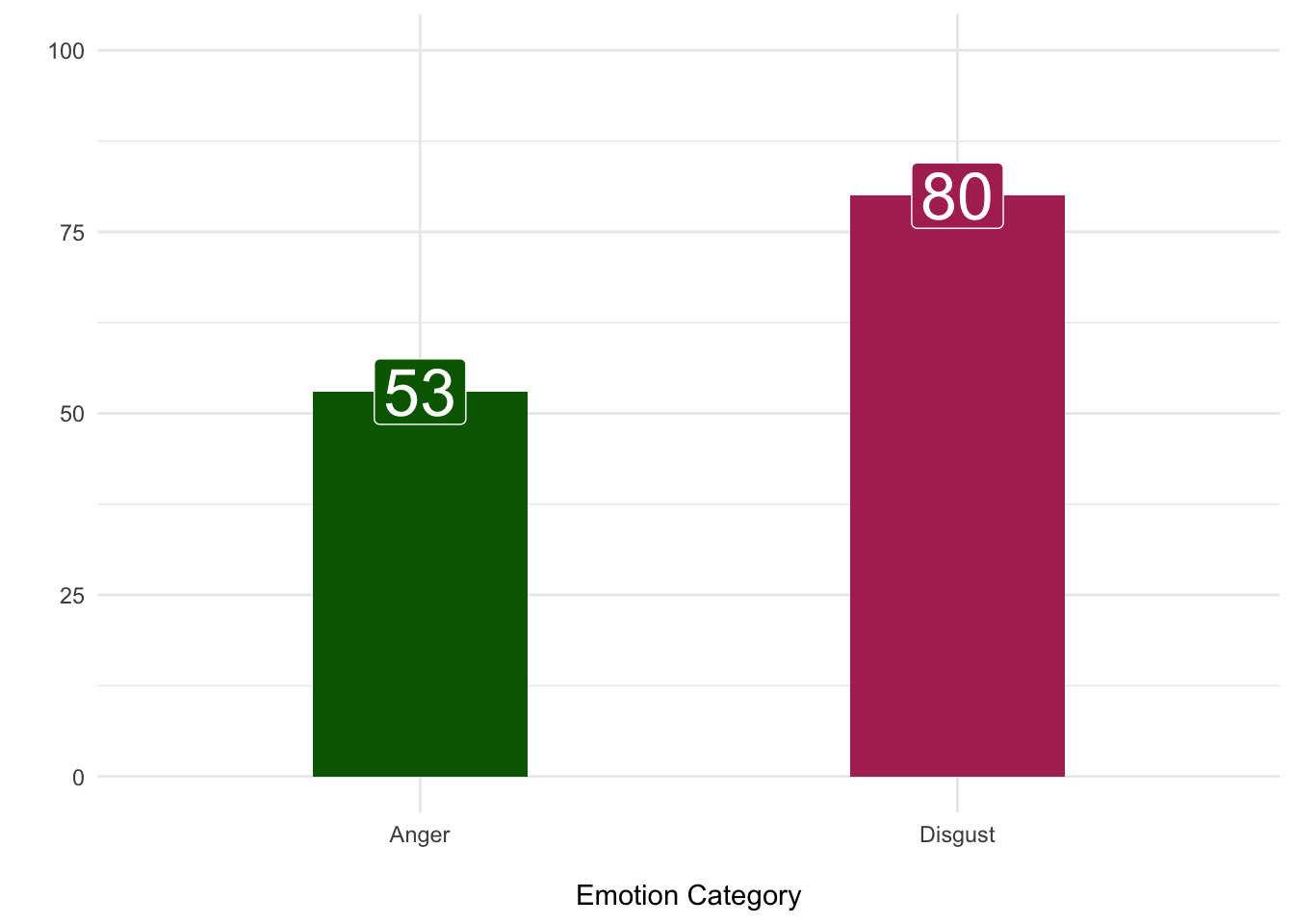
--- title: "Perceptions of Creepiness" author: "Terri Payne, Joe DeVita & David Brocker" format: html: code-fold: true code-link: true code-tools: true toc: true toc-depth: 3 toc-location: left editor: visual theme: light: flatly dark: darkly lightbox: true --- # Hypotheses # Stimuli ## Data Processing ```{r} #| message: false #| warning: false # Load in packages library (haven) # Import SPSS library (dplyr) # Wrangling Data library (tibble) # Nicer Printing library (tidyr) # Manipulate Data library (ggplot2) # Plotting Data library (purrr) # Dealing with lists library (labelled) # For dealing with labels library (forcats) # for handling categories library (huxtable) # For making nice tables library (afex) # for nice ANOVAS library (broom) # Cleaning up stats library (stringr) # Text Manipulation library (janitor) # Cleaning up names library (tidytext) # Word Count library (patchwork) # Combining Graphs library (readxl) # Read in excel library (ggtext) # Add text elements to plots suppressPackageStartupMessages (library (googleVis))# Custom Functions <- function (data,x){<- |> select ({{x}}) |> pull ()<- |> tabyl () |> select (- (starts_with ("val" ))) |> # Ignore Error for Now,,, adorn_pct_formatting (,,,percent) |> rename_with (str_to_sentence) |> hux () |> theme_article () |> set_align (everywhere,everywhere,"." )1 ,] <- c (str_to_sentence (x),"" ,"" )<- function (string) {<- str_trim (string)<- str_remove_all (string, "[[:punct:]]" )# Read Data <- read_spss ("Perceptions+of+Creepiness_February+19%2C+2024_16.43.sav" )# Clean Data <- |> # Only look at complete cases filter (Finished == 1 ) |> # Only use 18+ cases filter (Age > 1 ) |> # Remove uneeded columns select (! StartDate: RecordedDate) |> select (! DistributionChannel: UserLanguage) |> select (! id: Ethnicity_Race_6_TEXT___Topics) |> rename (Creepy_Occ_8 = Occ_8)``` ### Demographics ```{r} # Subset Demographic data <- |> select (Gender,Religion,Ethnicity_Race,Age) |> mutate (# Get Labels of Demographic variables Gender = sjlabelled:: get_labels (cr_cln$ Gender)[cr_cln$ Gender],Religion = sjlabelled:: get_labels (cr_cln$ Religion)[cr_cln$ Religion],Ethnicity_Race = sjlabelled:: get_labels (cr_cln$ Ethnicity_Race)[cr_cln$ Ethnicity_Race],Age = sjlabelled:: get_labels (cr_cln$ Age)[cr_cln$ Age])# Apply Custom Function <- discrete_tab (demo,"Gender" )<- discrete_tab (demo,"Ethnicity_Race" )<- discrete_tab (demo,"Religion" )<- discrete_tab (demo,"Age" )|> add_rows (eth) |> add_rows (rel) |> add_rows (age) |> # Add Header Row insert_row ("Variable" ,"N" ,"Percent" ) |> set_top_border (row = 1 : 3 ,1 : 3 ) |> set_align (col = 1 , value = "left" ) |> set_align (1 ,1 ,"center" ) |> set_bottom_border (row = nrow (all), col = ncol (all), value = .4 ) ``` ### Creepy Occupations ```{r} # Get Occupation Labels <- |> select (contains ("Occ" )) <- map_df (occ_lab,get_label_attribute)# Isolated Occupations <- |> pivot_longer (cols= Creepy_Occ_2: Creepy_Occ_22,names_to = "occ" ) |> select (value)# Occupation Analysis <- |> rename_at (vars (contains ("occ" )), ~ occ$ value) |> pivot_longer (cols = Clown: Meterologist,names_to = "jobs" ,values_to = "score" ) |> mutate (jobs = as.factor (jobs),color = ifelse (jobs %in% c ("Funeral Director" ,"Sex Shop Owner" ,"Taxidermist" ,"Clown" ),"maroon" ,"grey" )) # Visualize |> ggplot (aes (score,fct_inorder (jobs))) + stat_summary (fun = "mean" ,geom = "bar" ,aes (fill = color)+ stat_summary (fun.data = "mean_se" ,geom = "errorbar" + theme_minimal () + labs (x = " \n " ,y = " \n " ,title = "How Creepy is your Job?" ,subtitle = "The <strong><span style = 'color:maroon;'>creepiest</span></strong> occupations replicate findings from McAndrew and Koehnke (2017)<br>" + coord_cartesian (xlim= c (1 ,5 )) + scale_fill_identity () + theme (plot.title.position = "plot" ,plot.title = element_text (face = "bold" ,size = 20 ),plot.subtitle = element_markdown ()``` ```{r} |> group_by (jobs) |> summarize (Mean = mean (score),SD = sd (score)|> arrange (desc (Mean)) |> rename (Occupation = jobs) |> hux () |> theme_article ()``` ## Emotional Perception ```{r} # 1 = Anger | 2 = Disgust <- |> select (Emotion) |> remove_labels () |> mutate (category = ifelse (Emotion == "1" , "Anger" ,"Disgust" )# Chi Square Test Shows More Endorsement for Disgust table (cr_emot$ category) |> chisq.test () |> tidy () |> rename (chi = statistic,df = parameter,p = p.value|> select (- method) |> select (chi,df,p) |> hux () |> theme_article ()``` ### Emotion Visualized ```{r} |> group_by (category) |> count () |> ggplot (aes (category,n,fill = category, label = n)) + geom_bar (stat = "identity" ,width = .40 ) + theme_minimal () + geom_label (size = 9 ,colour = "white" ) + labs (x = " \n Emotion Category" ,y = "" + ylim (0 ,100 )+ theme (legend.position = "none" + scale_fill_manual (values = c ("darkgreen" ,"maroon" ))``` ## Moral Perception ```{r} <- |> remove_labels ()# One Sample T-Test showing Creepy People are thought to possess 'bad' moral character |> rowwise () |> select (bad_or_good: trustworthy_r) |> mutate (character = mean (c_across (bad_or_good: trustworthy_r))|> select (character) |> ungroup () |> t.test (mu = 4 ) |> tidy () |> rename (Mean = estimate,t = statistic, p = p.value,df = parameter|> mutate (` CI[ll,uu] ` = paste0 ("[" ,|> round (0 ),"," ,conf.high |> round (0 ),"]" )|> select (- conf.low,- conf.high,- method,- alternative) |> relocate (p, .after = last_col ())``` ## Face Ratings ## Qualitative Analyses ### Creepiness Scenario ```{r} <- |> select (Creepiness_Scenario) |> filter (! str_detect (Creepiness_Scenario,"test|TEST" )) |> separate_longer_delim (cols = Creepiness_Scenario,delim = c ("," )) |> separate_longer_delim (cols = Creepiness_Scenario,delim = c ("and" )) |> separate_longer_delim (cols = Creepiness_Scenario,delim = c (";" )) |> mutate (Creepiness_Scenario = str_trim (Creepiness_Scenario,"left" ),Creepiness_Scenario = str_to_lower (Creepiness_Scenario),length = str_length (Creepiness_Scenario),speaker = row_number ()|> filter (str_detect (Creepiness_Scenario,"^ \\ b" )) |> filter (length > 10 ) |> slice_sample (n = 20 )gvisWordTree (chartid = "scenario" ,textvar = "Creepiness_Scenario" ,options= list (width= 2000 , height= 1000 )) |> plot (tag = NULL )``` ### Creepy Hobbies ```{r} <- |> select (Creepy_Hobby) |> # Remove single answer and placeholder text filter (! str_detect (Creepy_Hobby,"^h|(s){3} \\ 1" )) |> # Separate by (, and or) separate_longer_delim (cols = Creepy_Hobby,delim = c ("," )) |> separate_longer_delim (cols = Creepy_Hobby,delim = c ("and" )) |> mutate (Creepy_Hobby = str_trim (Creepy_Hobby,"left" ),Creepy_Hobby = str_to_lower (Creepy_Hobby)<- gvisWordTree (data = hob, textvar = "Creepy_Hobby" ,chartid = "hobby" ,options= list (width= 2000 , height= 1000 )) ``` ```{=html} `r creep_gv |> print()` ```