onefact <-data.frame(groups =rep(c("Control","Treatment 1", "Treatment 2"), each =20),score =c(rnorm(20,10),rnorm(20,15),rnorm(20,22)))head(onefact)
groups score
1 Control 10.996546
2 Control 9.753324
3 Control 10.896292
4 Control 10.103684
5 Control 9.839047
6 Control 10.289613
We have three independent variables, or conditions, control, treatment 1 and treatment 2. We have one dependent variable, some idea of “score” or our dependent variabe.
The ANOVA is analyzed through the use of the aov function. Remember to save the analysis as a model so you can use it later if you need to do any post-hoc tests/unplanned comparisons.
Df Sum Sq Mean Sq F value Pr(>F)
groups 2 1518.4 759.2 1132 <2e-16 ***
Residuals 57 38.2 0.7
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
This produces a sum of squares and mean squares for the between subjects factor, groups. It also produces a sum of squares and mean squares for the within subjects factor, also called the residuals, or the error.
From this we get one F-value.
The current design will not help us too much so we need to move on to another design, the two factor between subjects ANOVA.
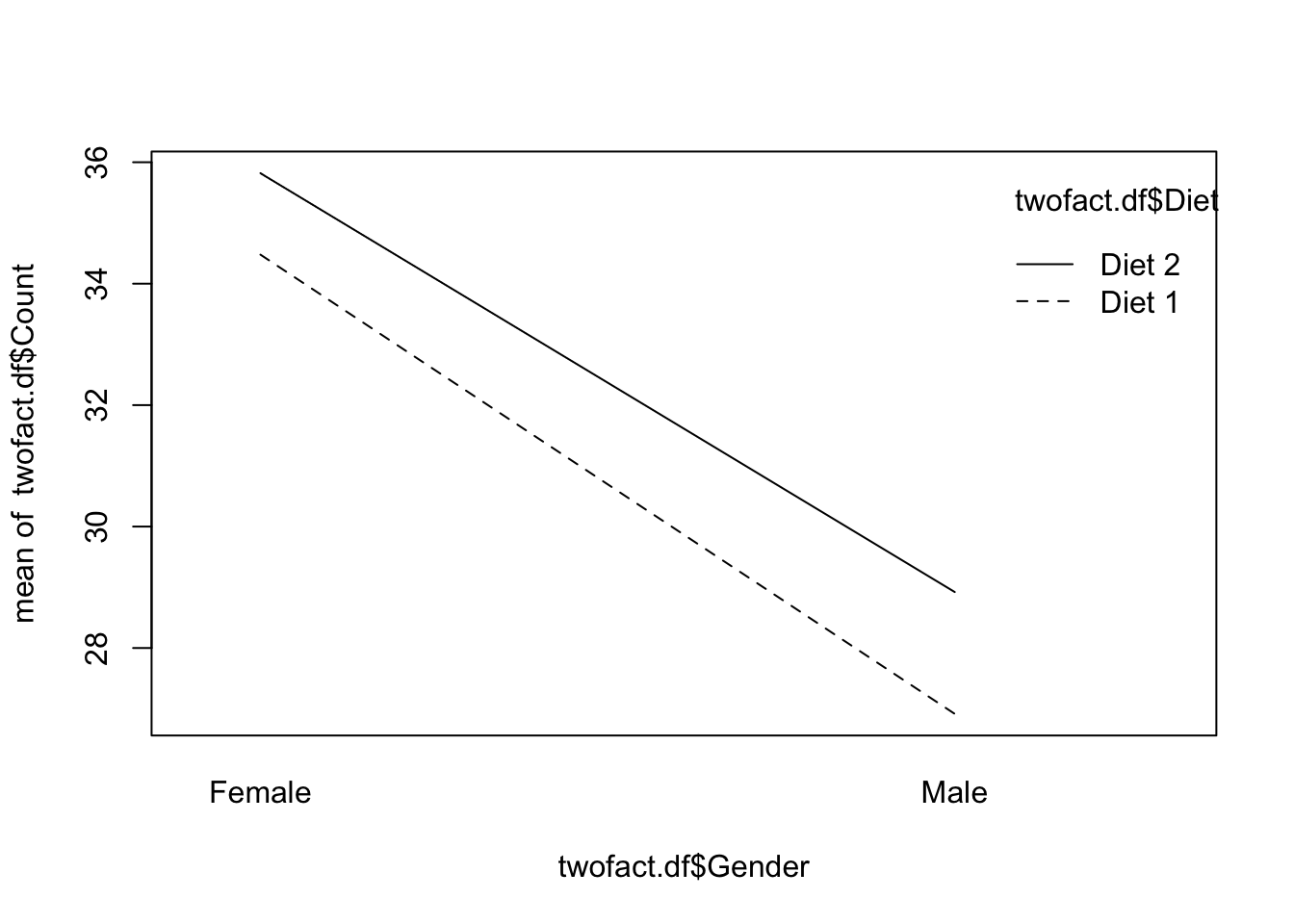
We can see that there are two levels of the independent variable (gender) and two levels of the independent variable (Diet) and one dependent variable, count.
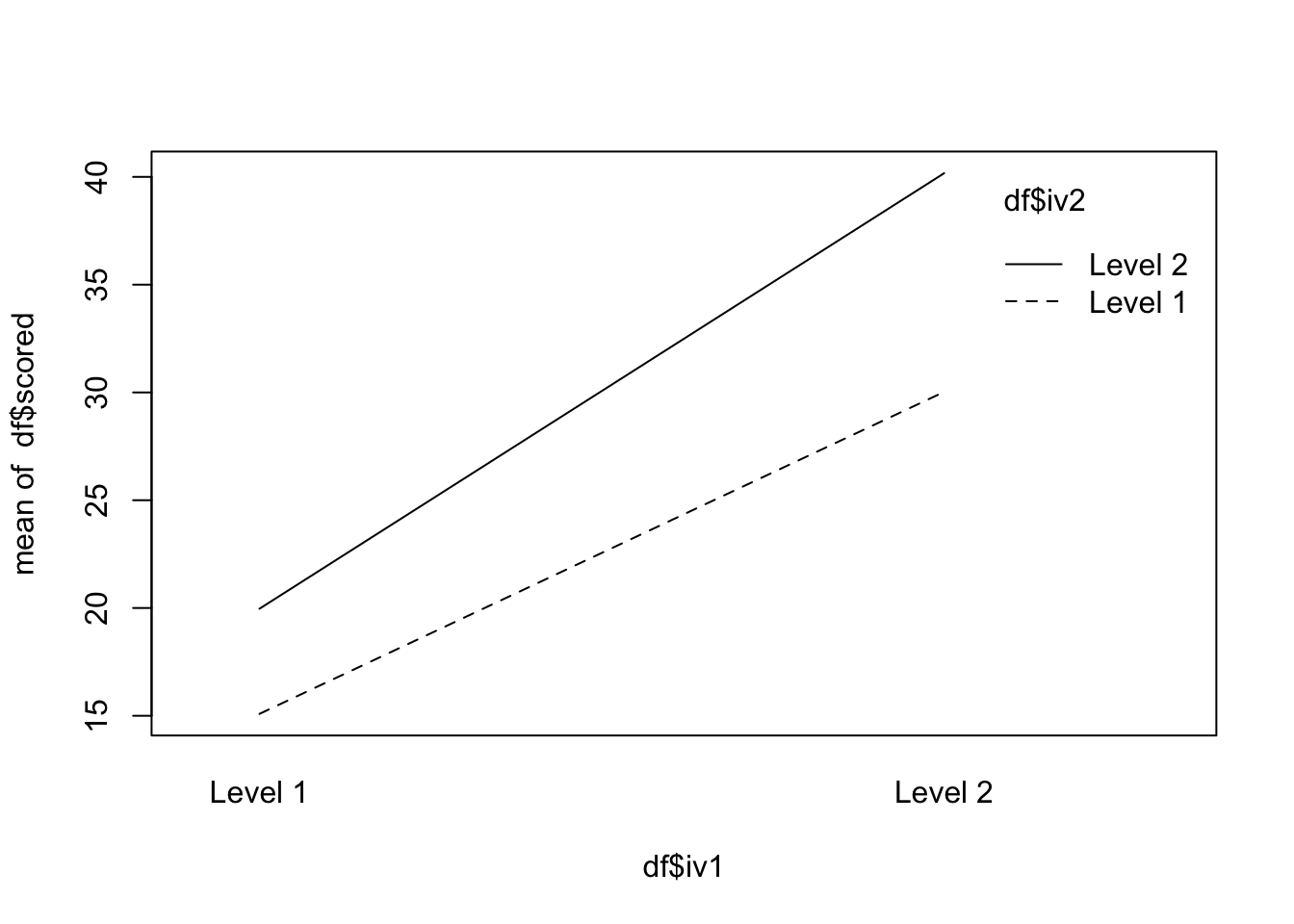
From this we will generate four sums of squares and four mean squares. - Sum of Squares for Factor A - Sum of Squares for Factor B - - Sum of Squares for the interaction between A and B - Sum of Squares within, or Error, or residual.
In a Two Factor Between Subjects ANOVA, a particular participant is only ever in one condition or group or treatment level.
In a Two Factor Within Subjects ANOVA, a particular participant is in each condition or group or treatment level.
Setting this data up uses the same principles as we have learned before.
The one major difference in the set-up of the data is that there is now a variable of the subject itself.
When we had a between subjects design, each participant was unique, with a within deisgn, each participant experiences every aspect of the experiment so it is reasonable that they may have an effect on the experiment itself.
Error: subject
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 1 113.9 113.9
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
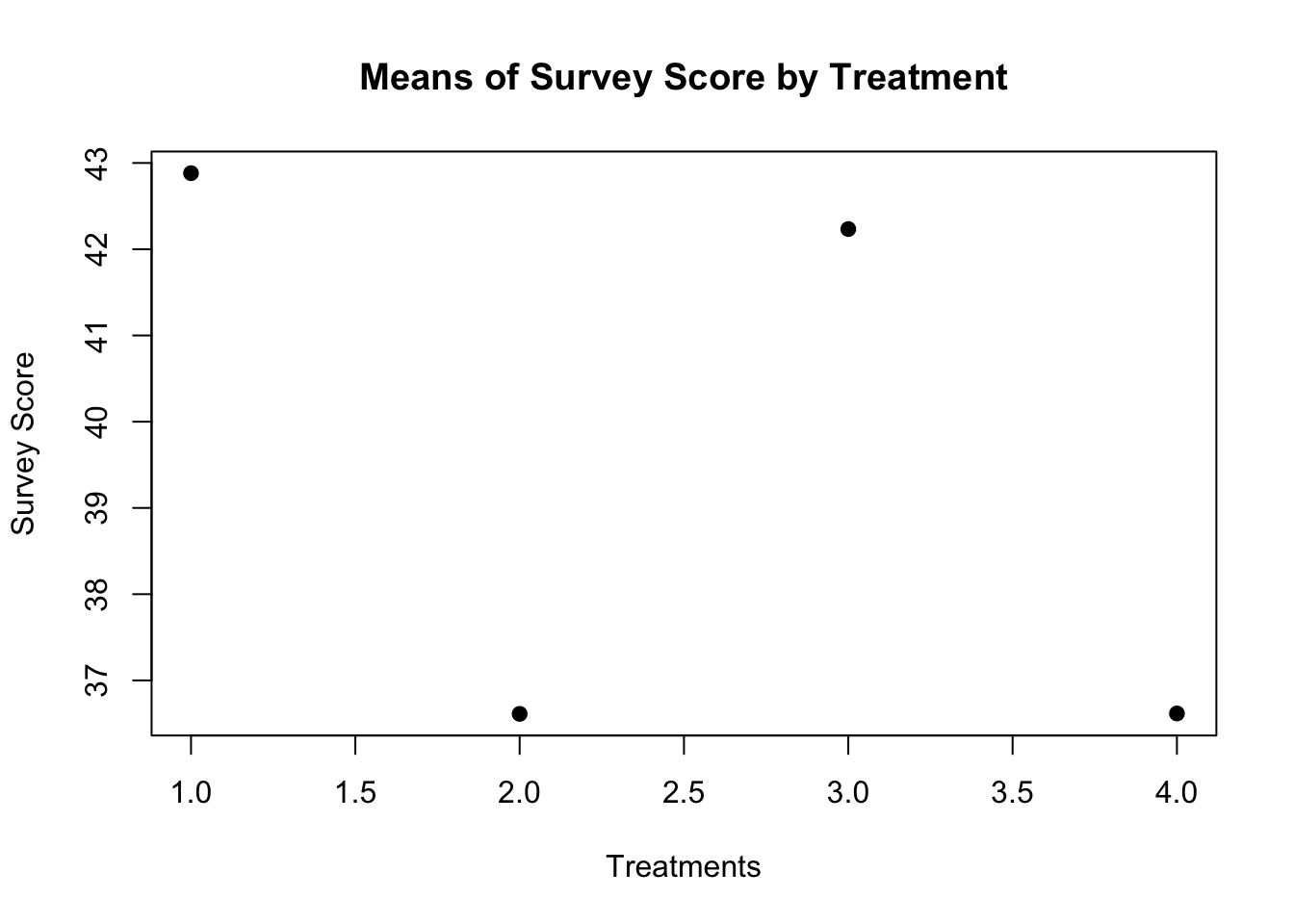
groups 3 355 118.4 0.303 0.823
Residuals 35 13665 390.4
When reporting these findings, you will ignore the subject variable and report the F-value for the grouping variable.
This particular finding should be reported as follows:
\(F(3,35) = .303, p >.05\)
The results of a one-factor within subjects ANOVA revealed that there does not appear to be any effect of treatment on survey score.
12.2 Effect Sizes
Most times you will want to report effect sizes for your experiment. Effect sizes help to tell you how much of your effect is due to your manipulation.
In this example, there does not appear to be an effect at all, but we will compute an effect size anyways.
We will be using the \(\omega^2\) effect size estimate.